최종 배포 후, 이제 뭐해야하지?

벌써 프론트엔드 개발을 업으로 삼은지 3년차가 되었다. 년차에 부끄럽게도, 사실 지금까지는 배포 이후를 깊게 고민해본 적이 없었다. 그동안 진행했던 사이드 프로젝트나 사내 서비스들은 굳이 검색엔진에 걸릴 필요가 없었고, 이미 운영 중인 서비스에 기능을 얹는 정도였기 때문에 배포 후에는 버그 픽스만 하면 된다고 생각했다.
하지만 이번에는 버셀로 ‘딸깍 배포를 하고 나서, 사이트가 검색엔진에 노출되게 만들려다 보니 예상보다 챙겨야 할 게 많다는 걸 깨달았다. 아무리 검색을 해봐도 내 사이트는 결과에 나타나지 않았고, 막막함이 컸다.
그래서 기초적인 부분부터 하나씩 정리해보기로 했다.
거창한 내용은 아니지만, 배포 후 검색엔진에 노출되기 위해 개발자가 해야 할 일들을 기록해두려 한다.
DNS 연결부터
검색엔진에 노출되려면 가장 먼저 해야 할 일은, 내가 구매한 도메인을 배포된 프로젝트와 제대로 연결하는 거였다. Vercel은 이 과정이 꽤 단순한 편이라, DNS 레코드만 바꿔주면 된다.
나는 도메인을 구매한 곳(가비아)에서 다음과 같이 설정했다.
| 타입 | 호스트 | 값/위치 | TTL | 우선순위 | 서비스 DNS 설정 |
|---|---|---|---|---|---|
| A | @ | 76.76.21.21 | 600 | DNS 설정 | |
| CNAME | www | cname.vercel-dns.com. | 600 | DNS 설정 |
이후 Vercel의 Domains → Add Domain 메뉴에서 해당 도메인을 추가하면 연결이 끝난다. 이 단계는 단순하지만, 검색엔진 입장에서는 "이 사이트가 실제로 존재한다"는 출발점이 되기 때문에 반드시 선행해야 한다
검색엔진에 소유권 인증하기
도메인을 연결했다고 해서 바로 검색 결과에 잡히는 건 아니다. 검색엔진에 “이 사이트는 내가 관리하는 사이트다”라는 소유권 인증 과정을 거쳐야 한다.
Google Search Console
구글에서는 여러 방식으로 소유권을 인증할 수 있다. DNS 레코드를 추가하거나, HTML 파일을 업로드하거나, HTML <meta> 태그를 넣는 방법이 있다.
나는 DNS TXT 레코드를 추가하는 방식을 사용했다.
| 방법 | 설명 |
|---|---|
| DNS 레코드 추가 | 도메인 관리 페이지에 TXT 레코드 입력 |
| HTML 파일 업로드 | 루트 경로에 인증용 파일 업로드 |
| HTML 메타 태그 | <head>에 인증용 <meta> 태그 삽입 |
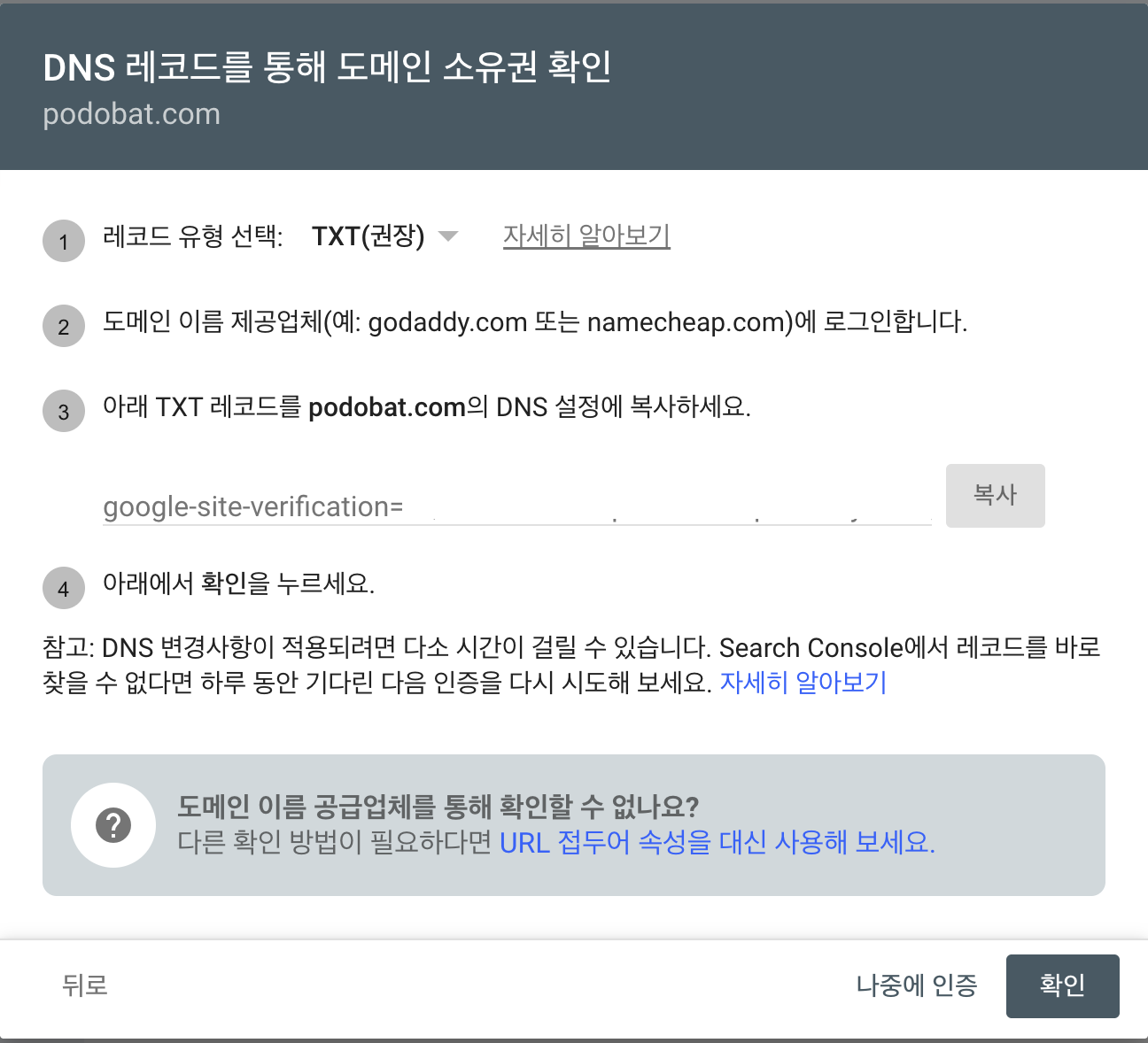

설정을 완료하면 Search Console에서 소유권이 확인된다.

이후에는 sitemap.xml 제출을 통해 구글이 페이지를 효율적으로 크롤링하도록 도와줄 수 있다.
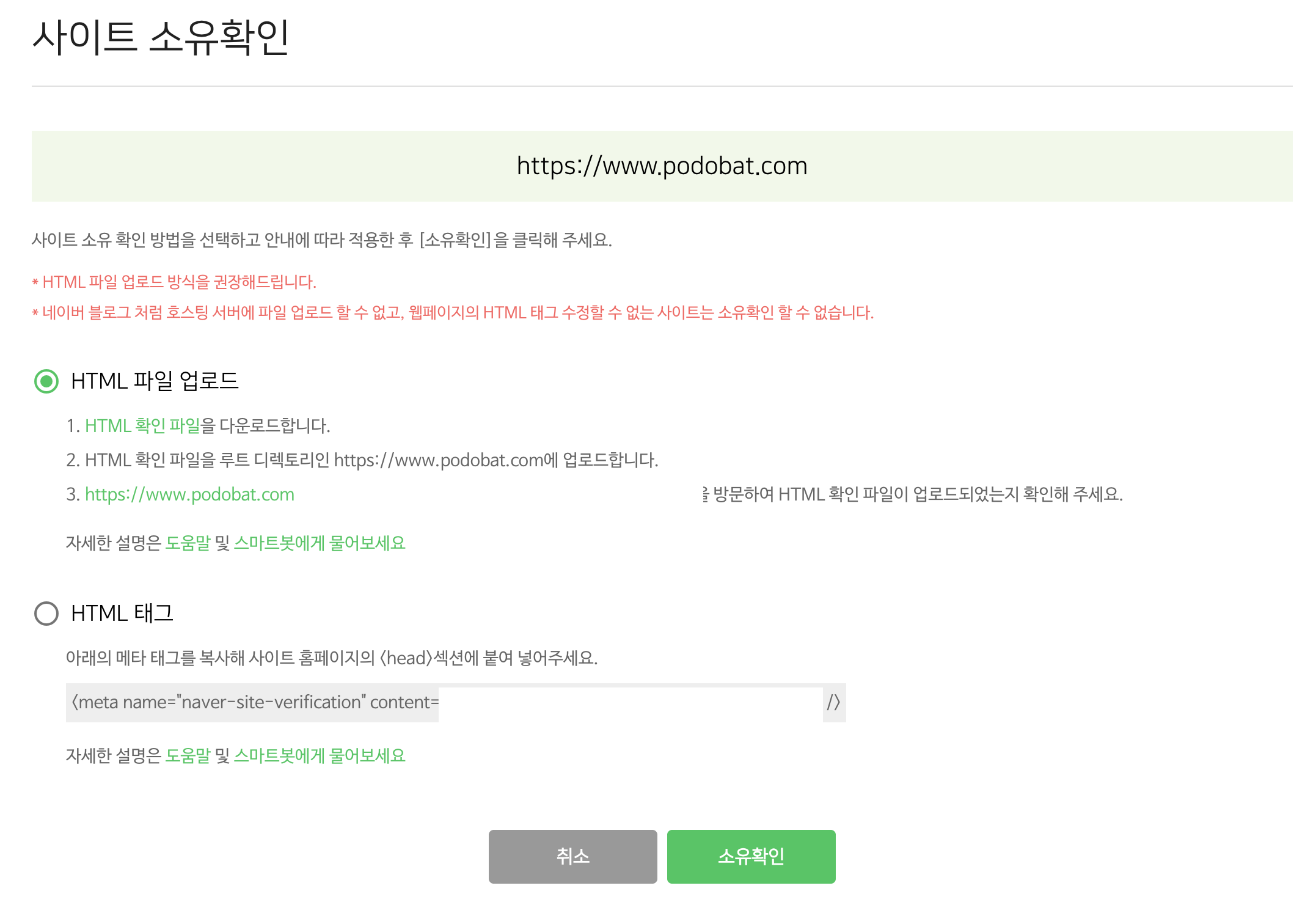
Naver Search Advisor
네이버도 비슷하다. 여러 방법 중에서 나는 HTML 메타 태그 삽입을 선택했다.
관리 화면에서 발급받은 <meta> 태그를 <head>에 추가하면 된다.
방법 설명
HTML 메타 태그 <head>에 네이버 인증 태그 삽입
HTML 파일 업로드 루트 경로에 인증용 파일 업로드
설정을 마치면 네이버 서치 어드바이저에서도 내 사이트가 정상적으로 확인된다.
Sitemap과 Robots.txt 설정하기
소유권 인증을 마쳤다면, 이제 검색엔진이 내 사이트를 제대로 읽을 수 있도록 sitemap.xml과 robots.txt를 제공해야 한다.
Sitemap: 사이트 내 주요 페이지들의 구조와 업데이트 일자를 알려주는 파일Robots.txt: 검색엔진 크롤러가 접근 가능한 경로와 차단할 경로를 지정하는 파일
Sitemap
Next.js에서는 next-sitemap, generateSitemaps, Next.js API 등 다양한 방법으로 생성할 수 있다.
나는 Next.js API 라우트를 활용했다.
정적 페이지는 직접 등록하고, 공지사항 같은 동적 페이지는 Supabase에서 불러와 sitemap을 동적으로 만들었다.
예시 코드
export default async function sitemap() {
const baseUrl = 'https://www.podobat.com';
// 정적 페이지들
const staticPages = [
{ url: `${baseUrl}/`, changefreq: 'daily', priority: 1 },
{ url: `${baseUrl}/about`, changefreq: 'monthly', priority: 0.8 },
{ url: `${baseUrl}/courses`, changefreq: 'weekly', priority: 0.9 },
];
// 동적 페이지들 (공지사항)
try {
const supabase = await createServerSupabaseClient();
const { data: notices } = await supabase
.from('notices')
.select('id, updated_at')
.eq('is_active', true)
.order('created_at', { ascending: false });
const noticePages: MetadataRoute.Sitemap = (notices || []).map((notice) => ({
url: `${baseUrl}/notices/${notice.id}`,
lastModified: new Date(notice.updated_at),
changeFrequency: 'weekly' as const,
priority: 0.6,
}));
return [...staticPages, ...noticePages];
} catch (error) {
console.error('Error generating sitemap:', error);
// 에러 발생 시 정적 페이지만 반환
return staticPages;
}
return [...staticPages];
}
이렇게 하면 /sitemap.xml 주소에서 자동으로 최신 데이터 기반의 사이트맵을 제공할 수 있다.
Robots.txt
검색엔진이 어디까지 크롤링할 수 있는지 알려주는 역할을 한다. Next.js에서는 아래처럼 간단하게 설정할 수 있다.
export default function robots() {
return {
rules: {
userAgent: '*',
allow: '/',
disallow: ['/mypage/', '/admin/', '/api/', '/login', '/privacy', '/terms'],
},
sitemap: 'https://www.podobat.com/sitemap.xml',
};
}
이제 구글과 네이버에 각각 생성된 sitemap.xml과 robots.txt를 제출하면, 검색엔진이 내 사이트 구조를 더 정확히 이해하고 크롤링할 수 있다.
메타데이터 설정하기
검색엔진이 사이트 구조를 이해하도록 돕는 게 sitemap이라면, 사용자가 링크를 공유했을 때 보이는 미리보기를 책임지는 건 메타데이터다.
카카오톡, 네이버 블로그, 페이스북 같은 곳에서 링크를 붙여봤는데 아무 정보도 안 뜬다면, 바로 이 부분이 빠져있기 때문이다.
Open Graph 태그란?
- 목적: 링크가 공유될 때 제목/설명/이미지를 보여주는 표준
- 형식: HTML
<head>안에<meta property="og:...">태그로 작성 - 효과: “이 사이트가 어떤 내용인지”를 한눈에 알 수 있어 클릭률을 높여준다
정적 페이지 예시
Next.js 13 이상에서는 metadata 객체를 활용하면 된다.
예를 들어 학원 소개 페이지(/about)는 다음처럼 작성할 수 있다:
import { Metadata } from 'next';
export const metadata: Metadata = {
title: '학원 소개 | 포도밭 국어논술',
description: '포도밭학원 소개 페이지입니다. 교육 철학과 수업 방식, 강사진을 확인할 수 있습니다.',
openGraph: {
title: '학원 소개 | 포도밭 국어논술',
description: '사람을 기르는 글쓰기, 세상을 여는 국어논술. 포도밭학원 소개 페이지입니다.',
url: 'https://www.podobat.com/about',
},
};

동적 페이지 예시
공지사항처럼 DB에서 가져오는 내용은 generateMetadata를 활용한다.
본문의 HTML 태그를 제거하고, 앞부분 160자만 잘라 description으로 설정했다.
export async function generateMetadata({ params }: NoticeDetailPageProps): Promise<Metadata> {
const { id } = params;
const notice = await getNoticeById(Number(id));
if (!notice) {
return { title: '공지사항을 찾을 수 없습니다', description: '요청하신 공지사항이 없습니다.' };
}
const cleanContent = notice.content.replace(/<[^>]*>/g, '').slice(0, 160);
return {
title: `${notice.title} | 포도밭 국어논술`,
description: cleanContent,
openGraph: {
title: notice.title,
description: cleanContent,
url: `https://www.podobat.com/notices/${notice.id}`,
type: 'article',
publishedTime: notice.createdAt,
authors: notice.authorName ? [notice.authorName] : undefined,
},
twitter: {
card: 'summary',
title: notice.title,
description: cleanContent,
},
};
}
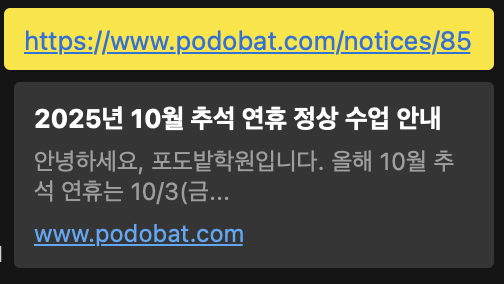
이렇게 하면 공지사항을 공유했을 때, 제목과 본문 요약이 깔끔하게 노출된다.
(선택) 사용자 추적 툴 적용하기
검색엔진 최적화가 끝났다면, 이제는 방문자가 어떻게 행동하는지를 살펴볼 차례다. 운영 중 발생하는 에러를 추적하고, 트래픽과 인터랙션을 분석할 수 있는 툴들을 붙여두면 서비스 개선에 큰 도움이 된다.
| 툴 | 목적 | 특징 |
|---|---|---|
| Sentry | 클라이언트 사이드 에러 로깅 | 에러 발생 시 스택트레이스와 사용자 환경 기록, 배포 버전별 이슈 추적 가능 |
| Vercel Analytics | 방문 통계 분석 | 페이지별 방문 수, 유입 경로, 국가·기기·OS 등 기본 분석 제공 |
| PostHog | 유저 행동 분석 | 버튼 클릭, 페이지 이동, 체류 시간 등 세밀한 사용자 인터랙션 추적 가능 |
이렇게 세 가지 정도만 세팅해두면,
- Sentry로는 에러를 실시간으로 확인하고,
- Vercel Analytics로는 전체 트래픽을 한눈에 파악하고,
- PostHog로는 구체적인 사용자 행동을 분석할 수 있다.

이번 과정을 거치면서, 단순히 “배포가 끝났다”는 게 개발의 끝이 아니라는 걸 배웠다. 검색엔진 노출, 메타데이터, 사용자 추적 같은 설정들이 쌓여야 비로소 진정한 서비스가 완성된다는 점을 확인할 수 있었다.
comments
loading…